Private 1st Solution
参加者の皆様お疲れ様でした。
運営の方々、本コンペを開催して下さり、誠にありがとうございました。
解法すべてを1つのnotebookに納めるのが難しいので、以下のgithubにコード一式と主要な出力ファイルを格納しました。
https://github.com/riron1206/probspace_religious_art_1st_solution
実験ごとにnotebookを作成したため、非常に確認しづらい構成になっていますが、もしよろしければレビューをお願い致します。
解法の概要
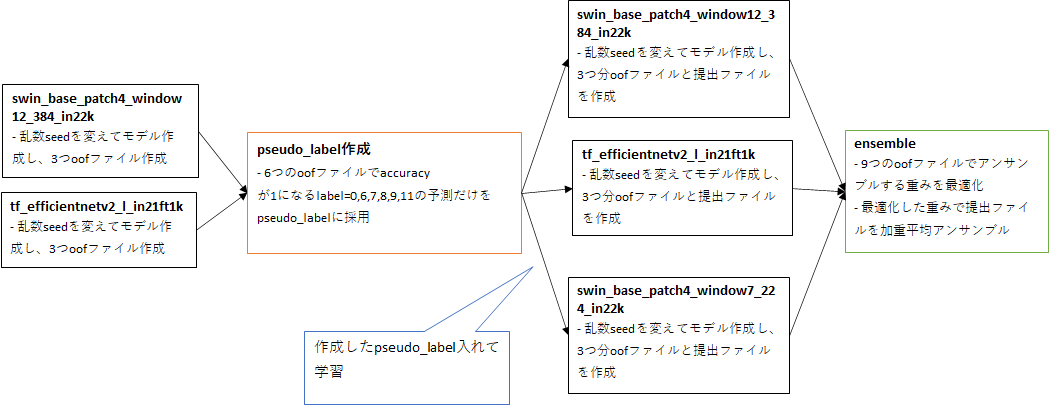
以下の流れでpseudo_labelと加重平均アンサンブルを行いました。
モデル
timm( https://github.com/rwightman/pytorch-image-models )の
SwinTransformer( https://arxiv.org/abs/2103.14030 )とEfficientNetV2( https://arxiv.org/abs/2104.00298 )のImagenet学習済みモデルを使用。
- pseudo_label作成で使用したモデル
- swin_base_patch4_window12_384_in22k (SwinTransformer)
- tf_efficientnetv2_l_in21ft1k (EfficientNetV2)
- 加重平均アンサンブルで使用したモデル
- swin_base_patch4_window12_384_in22k (SwinTransformer)
- tf_efficientnetv2_l_in21ft1k (EfficientNetV2)
- swin_base_patch4_window7_224_in22k (SwinTransformer)
- パラメータ
- batch_size: 8や16(モデルによって変えた)
- epoch: 35や50(モデルによって変えた)
- optimizer: radam+lookahead
- lr: 1e-3~1e-06
- scheduler: CosineAnnealingLR(T_max=epoch)
Validation
StratifiedKFold(n_splits=5)
Augmentation
cutmixと以下のalbumentations( https://github.com/albumentations-team/albumentations )の組み合わせ。
import albumentations as A
from albumentations.pytorch import ToTensorV2
if data == "train":
return A.Compose(
[
A.Resize(CFG.size, CFG.size),
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(p=0.5),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], max_pixel_value=255.0, p=1.0,),
A.OneOf([
A.ToSepia(p=0.5),
A.ToGray(p=0.5),
], p=0.5),
A.CoarseDropout(p=0.5),
A.Cutout(p=0.5),
ToTensorV2(),
]
)
TTA
HorizontalFlipのみ。
pseudo_label
- データが少ないので、ラベルノイズが1件でもあるとLB大幅に悪化すると考え、できるだけ正しい疑似ラベルを作るようにしました。
- trainデータで3seed分学習した swin_base_patch4_window12_384_in22k と tf_efficientnetv2_l_in21ft1k のOut Of Fold(oof)はlabel=0,6,7,8,9,11の予測についてはaccuracy=1になったので、label=0,6,7,8,9,11と予測したtestデータ131件だけをpseudo_labelに採用しました。
Ensemble
- pseudo_labelもtrainデータに入れて3seed分学習した swin_base_patch4_window12_384_in22k, tf_efficientnetv2_l_in21ft1k, swin_base_patch4_window7_224_in22k のoofから、加重平均アンサンブルする重みを最適化しました。
- 重みはアンサンブルする提出ファイルのlabel単位で計算したので、アンサンブルする提出ファイル数(=9)×label数(=13)の行列になっています。
イメージしにくいと思うので、気になる方はコードを確認してみてください。